

به گزارش ایسنا و به نقل از نیچر، «دومینکو ماسترودیکاسا» (Domenico Mastrodicasa) رادیولوژیست دانشکده پزشکی دانشگاه واشنگتن سیاتل در آمریکا است. او زمانی که در نوشتن مقاله پژوهشی خود دچار مشکل شده بود، به چت جیپیتی روی آورد؛ چت باتی که در عرض چند ثانیه تقریباً به هر سؤالی پاسخهای روان میدهد. ماسترودیکاسا میگوید: من از آن به عنوان ابزاری برای بررسی اعتبار ایدههای خودم استفاده میکنم و با استفاده از آن میتوانم نوشتههای آماده انتشار مقالهام را خیلی سریعتر تولید کنم.
ماسترودیکاسا یکی از پژوهشگران بسیاری است که از ابزارهای هوش مصنوعی مولد برای نوشتن متن یا کدنویسی استفاده میکند. او برای استفاده از چت جیپیتی پلاس که نسخه اشتراکی ربات مبتنی بر مدل زبانی بزرگ (LLM) جیپیتی-۴ است، پول پرداخت میکند و چندبار در هفته از آن استفاده میکند. او این ابزار را بهویژه برای پیشنهاد راههای واضحتر برای انتقال ایدههایش مفید میداند.
اگرچه نظرسنجی Nature نشان میدهد که دانشمندانی که به طور منظم از مدلهای زبانی بزرگ یا LLMها استفاده میکنند، هنوز در اقلیت هستند، بسیاری انتظار دارند که ابزارهای مولد هوش مصنوعی به دستیاران عادی نوشتن نوشتهها، گزارشهای داوری و برنامههای گرنت یا کمکهای مالی تبدیل شوند.
اینها تنها برخی از راههایی هستند که هوش مصنوعی میتواند از طریق آن ارتباطات علمی و انتشارات را متحول کند. در حال حاضر ناشران علمی با استفاده از هوش مصنوعی مولد ابزارهای جستجوی علمی و ویرایش و خلاصهسازی سریع مقالات را آزمایش میکنند. بسیاری از پژوهشگران فکر میکنند که غیر انگلیسیزبانها میتوانند بیشترین بهره را از این ابزارها ببرند. برخی هوش مصنوعی را راهی برای دانشمندان میدانند تا به طورکلی درباره نحوه گردآوری دادهها و خلاصه کردن نتایج تجربی تجدیدنظر کنند. آنها میتوانند از مدلهای زبانی بزرگ برای انجام بیشتر این کارها استفاده کنند و زمان کمتری را برای نوشتن مقالات صرف کنند و زمان بیشتری را برای انجام آزمایشات اختصاص دهند.

«مایکل آیزن» (Michael Eisen)، زیستشناس محاسباتی در دانشگاه کالیفرنیا برکلی که سردبیری مجله eLife را نیز برعهده دارد، میگوید: هدف هیچکس واقعاً نوشتن مقاله نیست؛ بلکه هدف انجام کار علمی است. او پیشبینی میکند که ابزارهای مولد هوش مصنوعی حتی بتوانند ماهیت مقاله علمی را نیز به طور اساسی تغییر دهند.
اما شبح خطا و بیدقتی، درستی و نادرست بودن این دیدگاه را تهدید میکند. مدلهای زبانی بزرگ یا LLMها، موتورهایی برای تولید اطلاعات دقیق نیستند، بلکه تنها خروجی را تولید میکنند که با الگوهای ورودی آنها متناسب باشد. ناشران نگران این هستند که افزایش استفاده از آنها منجر به تعداد بیشتری از نوشتههای بیکیفیت یا پرخطا شود و احتمالاً سیلابی از نوشتههای تقلبی با کمک هوش مصنوعی ایجاد شود.
«لورا فیتهام» (Laura Feetham)، ناظر داوری و بررسی همتایان انتشارات IOP در بریستول انگلستان که مجلات در زمینه علوم فیزیک را منتشر میکند، میگوید: هر چیز مخربی مانند این، میتواند نگرانکننده باشد.
سیل تقلبها
ناشران علمی و دیگران، طیف وسیعی از نگرانیها را در مورد تاثیرات بالقوه هوش مصنوعی مولد مطرح کردهاند. «دنیل هوک» (Daniel Hook) مدیر اجرایی Digital Science که یک شرکت تحقیقاتی-تحلیلی در لندن است، میگوید: دسترسی به ابزارهای مولد هوش مصنوعی میتواند تهیه مقالات بیکیفیت را آسانتر کند و در بدترین حالت، یکپارچگی و درستی تحقیقات را به خطر بیندازد. او میگوید: ناشران کاملاً حق دارند که بترسند.

در برخی موارد، پژوهشگران اعتراف کردهاند که از چت جیپیتی برای کمک به نوشتن مقالات استفاده کردهاند، بدون اینکه این واقعیت را افشا کنند. این عمل پژوهشگران زمانی فاش شده بود که فراموش کرده بودند نشانههای استفاده از چت جیپیتی مانند ارجاع جعلی یا پاسخ از پیش برنامهریزیشده را که نشاندهنده آن است که از نرمافزار مبتنی بر مدل زبانی هوش مصنوعی استفاده شده است، حذف کنند.
ناشران تنها در حالت ایدهآل میتوانند متن تولیدشده توسط مدلهای زبانی بزرگ را تشخیص دهند. در عمل، ابزارهای تشخیص هوش مصنوعی تاکنون نتوانستهاند چنین متنی را به طور قابل اطمینان شناسایی کنند؛ در عین حال گاهی متن نوشتهشده توسط انسان را نیز به عنوان محصول هوش مصنوعی علامتگذاری میکنند.
اگرچه توسعهدهندگان مدلهای زبانی بزرگ تجاری، در حال کار بر روی واترمارک کردن خروجیهای تولید شده توسط مدلهای زبانی بزرگ هستند تا آنها را قابل شناسایی کنند؛ ولی هنوز هیچ شرکتی این واترمارک را برای متن ارائه نکرده است. «ساندرا واکتر» (Sandra Wachter)، پژوهشگر حقوقی دانشگاه آکسفورد انگلستان که بر روی مفاهیم اخلاقی و قانونی فناوریهای نوظهور تمرکز دارد، میگوید: هرگونه واترمارکی قابل حذف است. او امیدوار است که قانونگذاران در سراسر جهان بر افشا یا واترمارک کردن مدلهای زبانی بزرگ اصرار کنند و حذف واترمارک را غیرقانونی کنند.
ناشران با ممنوع کردن استفاده از مدلهای زبانی بزرگ (همانکاری که «انجمن آمریکایی پیشرفت علم» و ناشر مجله ساینس (Science) انجام داده است) یا در بیشتر موارد با اصرار بر شفافیت (همان سیاستی که مجله نیچر "Nature" و بسیاری از مجلات دیگر در پیش گرفتهاند)، به این موضوع نزدیک میشوند.
مطالعهای که ۱۰۰ ناشر و مجله مورد بررسی قرار دادند، نشان میدهد که تا ماه می (اردیبهشت ماه سال جاری)، ۱۷ درصد از ناشران و ۷۰ درصد از مجلات، شیوهنامههایی را برای نحوه استفاده از هوش مصنوعی مولد منتشر کردهاند. «جیوانی کاچیامانی» (Giovanni Cacciamani)؛ متخصص اورولوژی دانشگاه کالیفرنیای جنوبی در لسآنجلس آمریکا که این مقاله را تالیف کرده است (البته این مقاله هنوز مورد بازبینی همتایان قرار نگرفته است)، میگوید: این شیوهنامهها در مورد نحوه استفاده از این ابزارها متفاوت هستند. او و همکارانش در حال کار با دانشمندان و سردبیران مجلات هستند تا مجموعهای از شیوهنامهها را توسعه دهند و به پژوهشگران در مورد نحوه گزارشدهی استفاده از مدلهای زبانی بزرگ کمک کنند.

بسیاری از ویراستاران نگران هستند که از هوش مصنوعی مولد برای تولید آسانتر مقالات جعلی اما باورپذیر، استفاده شود. شرکتهایی به کارخانههای مقالهسازی معروفند و نوشتهها یا جایگاههای نویسندگی را به پژوهشگرانی که میخواهند برونداد انتشارات خود را افزایش دهند، میفروشند. این کارخانههای مقالهسازی میتوانند از ابزارهای هوش مصنوعی سود ببرند. سخنگوی نشریه «ساینس» به «نیچر» گفته است که مدلهای زبانی بزرگ مانند چت جیپیتی میتواند مشکل کارخانههای مقالهسازی را تشدید کند.
یکی از پاسخها به این نگرانیها میتواند این باشد که برخی از مجلات رویکردهای خود را تقویت کنند تا بتوانند واقعی بودن نویسندگان و اینکه آیا خود آنها تحقیقی که ارائه کردهاند را انجام دادهاند، تایید کنند. «واکتر» میگوید: برای مجلات مهم است که بفهمند آیا نویسنده مقاله واقعاً کاری که ادعا میکند را انجام داده است یا خیر.
«بِرند پولوِرر» (Bernd Pulverer) رئیس انتشارات علمی «EMBO Press» در هایدلبرگ آلمان میگوید که در این انتشارات، نویسندگان باید تنها از طریق پستهای الکترونیک سازمانی قابل تایید برای ارسال مقاله اقدام کنند و کارکنان تحریریه، نویسندگان و داوران را در تماسهای ویدئویی ملاقات میکنند تا از هویت آنها اطمینان حاصل کنند. او اضافه میکند که مؤسسات پژوهشی و سرمایهگذاران نیز باید بر برونداد کارکنان خود و بر دریافتکنندگان گرنتها یا کمکهای مالی، نظارت داشته باشند. این چیزی نیست که بتوان آن را به طور کامل به مجلات واگذار کرد.
برابری و نابرابری
هنگامی که «نیچر» از پژوهشگران خود در مورد اینکه «فکر میکنند بزرگترین مزایای هوش مصنوعی مولد برای علم چه باشد؟» نظرسنجی کرد، بیشترین پاسخ این بود که این ابزار به پژوهشگرانی که انگلیسی زبان اولشان نیست، کمک میکند. «تاتسویا آمانو» (Tatsuya Amano) دانشمند محیط زیست دانشگاه کوئینزلند استرالیا میگوید: استفاده از ابزارهای هوش مصنوعی میتواند برابری را در علم بهبود بخشد. آمانو و همکارانش بیش از ۹۰۰ دانشمند محیطزیست را که حداقل یک مقاله به زبان انگلیسی نوشته بودند را مورد بررسی قرار دادند. در میان پژوهشگران تازهکار، غیر انگلیسیزبانان گفتهاند که مقالات آنها دو برابر بیشتر از کسانی که انگلیسی زبان بومی آنها است، به دلیل مسائل نوشتاری رد شده است. همچنین کسانی که زبان بومی انگلیسی دارند، زمان کمتری را برای نوشتن مطالب ارسالی خود صرف میکنند. چت جیپیتی و ابزارهای مشابه میتواند برای این پژوهشگران کمک بزرگی باشد.
تاثیرات هوش مصنوعی مولد
هنگامی که در یک نظرسنجی در «نیچر» در مورد هوش مصنوعی مولد مانند مدلهای زبانی بزرگ سؤال پرسیده شد، پاسخدهندگان تاکید کردند که ترجمه، کدنویسی و خلاصههای تحقیقاتی بیشترین استفاده را دارند.
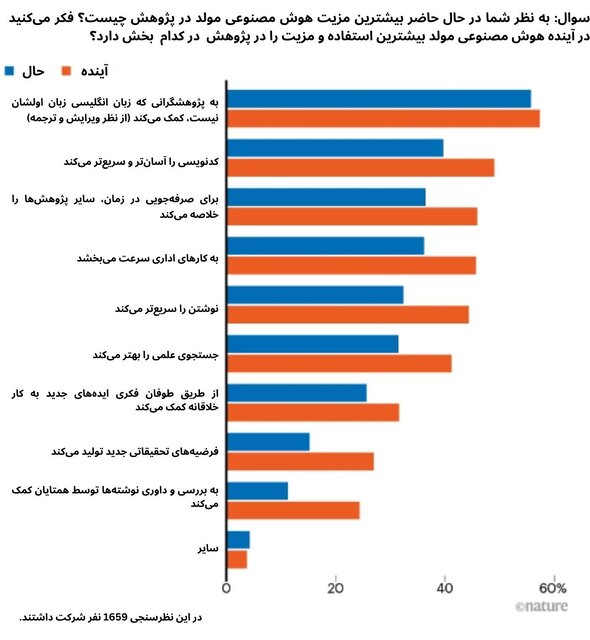
«آمانو» که زبان اول او ژاپنی است، چت جیپیتی را آزمایش کرده است و میگوید که استفاده از این ابزار شبیه به کار با یک همکار انگلیسیزبان بومی است؛ اگرچه که گاهی اوقات پیشنهادات این ابزار، انتظارات را برآورده نمیکند. او در ماه مارس پس از ممنوع شدن استفاده از ابزارهای مولد هوش مصنوعی در نشریات، سرمقالهای در مجله «ساینس» نوشت. با این استدلال که تا زمانی که نویسندگان استفاده از این ابزارها را افشا کنند، این استفاده میتواند انتشارات علمی را عادلانهتر کند. این افشا میتواند به صورت قرار دادن نسخه اصلی مقاله درکنار نسخه ویرایششده آن توسط هوش مصنوعی باشد.
مدلهای زبانی بزرگ با اولین نرمافزاری که بتواند با کمک هوش مصنوعی نوشتهها را بهتر کند، فاصله زیادی دارند. اما «ایرنه لی» (Irene Li) ، پژوهشگر هوش مصنوعی در دانشگاه توکیو میگوید که هوش مصنوعی به سادگی بسیار انعطافپذیر است. او قبلاً از نرمافزار Grammarly که یک برنامه اصلاح گرامر و املای مبتنی بر هوش مصنوعی است، برای بهتر شدن نوشتههای انگلیسی استفاده میکرد، ولی در حال حاضر به چت جیپیتی نقل مکان کرده چون این ابزار همهکاره است و در دراز مدت ارزش بیشتری را ارائه میدهد. همچنین او به جای پرداخت هزینه برای چندین ابزار، میتواند فقط در یک ابزار که همه این کارها را انجام میدهد، مشترک شود.
«چاوی چاوهان» (Chhavi Chauhan)؛ متخصص اخلاق هوش مصنوعی که مدیریت توسعه علمی را در انجمن آمریکایی آسیبشناسی پژوهش در مریلند آمریکا نیز بر عهده دارد، میگوید: با این حال روشی که در آن مدلهای زبانی بزرگ توسعه مییابند، ممکن است نابرابریها را تشدید کند. «چاوهان» نگران است که برخی از مدلهای زبانی بزرگ رایگان، برای اینکه بتوانند از عهده هزینههای توسعه و اجرای آنها برآیند، در آینده گران شوند. همچنین اینکه اگر ناشران از ابزارهای تشخیص مبتنی بر هوش مصنوعی استفاده کنند، به احتمال زیاد متن نوشتهشده توسط افراد انگلیسیزبان غیربومی را به عنوان متن نوشتهشده توسط هوش مصنوعی علامتگذاری کند. مطالعهای که در ماه جولای (تیرماه) منتشر شد، نشان داد که این اتفاق در نسل فعلی ردیابهای جیپیتی رخ میدهد. او میگوید: ما متوجه نابرابریهایی که این مدلهای هوش مصنوعی مولد ایجاد میکنند، نمیشویم.
چالشهای بازبینی توسط همتایان
مدلهای زبانی بزرگ یا LLMها میتوانند برای داوران مقالات نیز یک موهبت باشند. «ماسترودیکاسا» میگوید: از زمانی که از چت جیپیتی پلاس به عنوان دستیار استفاده میکند، او توانسته درخواستهای داوری بیشتری را بپذیرد و از آن برای بهتر کردن متن نظرات خود استفاده کند؛ البته او متن مقالات و اطلاعات آنها را در این ابزار آنلاین، آپلود نمیکند. او میگوید: «وقتی یک مقاله پیشنویس برای داوری دارم، میتوانم آن را به جای چند روز در چند ساعت اصلاح کنم. من فکر میکنم اینکه استفاده از این ابزار به بخشی از جعبه ابزار ما تبدیل شود، غیر قابل اجتناب است.
«کریستوف اشتاینبک» (Christoph Steinbeck) پژوهشگر شیمی انفورماتیک دانشگاه فردریش شیلر در آلمان، چت جیپیتی پلاس را برای تولید خلاصههای سریع از نسخههای پیشچاپی که او بررسی میکند، مفید یافته است. او خاطر نشان میکند که نسخههای پیشچاپ از قبل آنلاین هستند، به همین دلیل موضوع محرمانه بودن آنها در میان نیست.
یکی از نگرانیهای کلیدی این است که پژوهشگران میتوانند به چت جیپیتی تکیه کنند تا با فکر کردن کمی داوری و بازبینی کنند. البته عمل سادهلوحانه درخواست مستقیم از یک مدل زبانی بزرگ برای بازبینی و داوری یک نوشته ارزش زیادی ندارد. این را محمد حسینی که در کتابخانه و مرکز آموزشی علوم سلامت گالتر در دانشگاه نورثوسترن شیکاگو آمریکا اخلاق و صداقت پژوهشی میخواند، میگوید.

بیشتر نگرانیهای اولیه در مورد استفاده از مدلهای زبانی بزرگ در داوری همتایان، در مورد محرمانگی بوده است. چندین ناشر از جمله «الزویر»، «تیلور اند فرانسیس» و انتشارات «آیاوپی»، پژوهشگران را از آپلود کردن نوشتهها و بخشهایی از متن در پلتفرمهای هوش مصنوعی مولد برای تولید گزارشهای داوری منع کردهاند. ترس آنها از این است که آپلود کردن این متنها بتواند به مجموعه دادههای آموزشی یک مدل زبانی بزرگ، بازخورد یا فیدبک بدهد (ممکن است که آپلودکردن این متنها هوش مصنوعی را آموزش دهد و دادههای مقالاتی که تا کنون منتشر نشده، وارد اطلاعات هوش مصنوعی شود) این کار شرایط قرارداد در مورد محرمانه نگهداشتن کار را نقض میکند.
در ماه ژوئن (خردادماه)، مؤسسه ملی بهداشت ایالات متحده به دلیل نگرانی بابت محرمانگی، استفاده از چت جیپیتی و سایر ابزارهای هوش مصنوعی مولد را برای داوری گرنتها و کمکهای مالی ممنوع کرد. دو هفته بعد نیز شورای پژوهش استرالیا به همین دلیل استفاده از هوش مصنوعی مولد را در طول بازبینی گرنت و کمکهای مالی ممنوع کرد. این اتفاق پس از آن افتاد که تعدادی از داوریها که به نظر میرسیده توسط چت جیپیتی نوشته شده باشند، به صورت آنلاین ظاهر شد.
یکی از راههای دور زدن مانع محرمانگی، استفاده از مدلهای زبانی بزرگ با هاست یا میزبانی خصوصی است. از این طریق میتوان مطمئن بود که دادهها به شرکتهایی که میزبان مدلهای زبانی بزرگ در فضای ابری هستند، بازخورد داده نمیشوند. دانشگاه ایالتی آریزونا در حال آزمایش هاستهای خصوصی بر اساس مدلهای اپن سورس یا منبع باز مانند Llama ۲ و Falcon هستند. نیل وودبری (Neal Woodbury)، مدیر ارشد علم و فناوری در شرکت university’s Knowledge، که به رهبران دانشگاه در مورد ابتکارات تحقیقاتی مشاوره میدهد، میگوید: «این یک مشکل قابل حل است».
«فیتهام» میگوید که اگر واضحتر بود که مدلهای زبانی بزرگ چگونه دادههایی که در آنها قرار میگیرند را ذخیره، محافظت و استفاده میکنند، میتوانستیم این ابزارها را در سیستمهای داوری ناشران ادغام کنیم. اگر از این ابزارها به درستی استفاده شود، فرصتهای خوبی وجود دارد. بیش از نیم دهه است که ناشران از ابزارهای هوش مصنوعی یادگیری ماشینی و پردازش زبان طبیعی برای کمک به بررسی همتایان و داوری استفاده می کنند. سخنگوی انتشارات وایلی میگوید که این شرکت در حال آزمایش هوش مصنوعی مولد برای کمک به انتخاب نوشتهها، انتخاب داوران و تایید هویت نویسندگان است.
نگرانیهای اخلاقی
با این حال برخی از پژوهشگران استدلال میکنند که مدلهای زبانی بزرگ برای اینکه در فرآیند انتشار علمی گنجانده شوند، از نظر اخلاقی مبهم هستند. «آیریس ون رویج» (Iris van Rooij)، دانشمند علوم شناختی در دانشگاه رادبود هلند میگوید: نگرانی اصلی در نحوه کار مدلهای زبانی بزرگ نهفته است: با جستجوی محتوای اینترنتی بدون نگرانی از سوگیری، رضایت یا حق چاپ. او میافزاید که هوش مصنوعی مولد «از نظر طراحی، یک سرقت ادبی خودکار» است؛ زیرا کاربران هیچ ایدهای ندازند که چنین ابزارهایی اطلاعات خود را از کجا تامین میکنند. او استدلال میکند که اگر پژوهشگران از این مشکل بیشتر آگاه بودند، خودشان نمیخواستند که از ابزارهای هوش مصنوعی مولد استفاده کنند.
برخی از سازمانهای خبری جستجوی رباتهای چت جیپیتی در سایتهایشان را مسدود کردهاند و گزارشهای رسانهها حاکی از آن است که برخی از شرکتها در فکر شکایتهای قضایی هستند. اگرچه ناشران علمی در سطح عمومی تا این حد پیش نرفتند، ولی انتشارات وایلی به نیچر گفته است که به دقت گزارشهای صنعتی و ادعای دعوی قضایی را زیر نظر دارند؛ چرا که مدلهای هوش مصنوعی مولد مواد محافظتشده را برای اهداف آموزشی جمعآوری میکنند و در عین حال هرگونه محدودیت موجود در آن اطلاعات را نادیده میگیرند». این ناشر همچنین خاطر نشان میکند که خواستار نظارت بیشتر از جمله شفافیت و رسیدگی به تعهدات ارائهدهندگان مدلهای زبانی بزرگ است.
حسینی که دستیار ویراستار مجله Accountability in Research انتشارات «تایلر اند فرانسیس» نیز است، پیشنهاد میکند که آموزش دادن مدلهای زبانی بزرگ در پیشینه علمی رشتههای خاص، میتواند یکی از راههای بهبود دقت و ارتباط خروجی آنها با دانشمندان باشد؛ اگر چه هیچ ناشری به «نیچر» نگفته است که این کار را انجام میدهد.
«جما دریک» (Gemma Derrick) که در دانشگاه بریستول انگلیس سیاست و فرهنگ پژوهشی میخواند، میگوید که نگرانی دیگر این است که اگر پژوهشگران شروع به تکیه به مدلهای زبانی بزرگ کنند، ممکن است مهارتهای بیانی آنها ضعیف شود. پژوهشگران تازهکار ممکن است مهارتهای لازم را برای انجام رفتار منصفانه و بازبینی یا داوریهای متعادل را از دست بدهند.
تغییر تحولآفرین
«پاتریک ماینو» (Patrick Mineault)، دانشمند ارشد یادگیری ماشین در مؤسسه هوش مصنوعی میلا - کبک کانادا میگوید: ابزارهای هوش مصنوعی مولد به طور گستردهتر این پتانسیل را دارند که نحوه چاپ و انتشار پژوهشها را تغییر دهند. این میتواند به این معنی باشد که در آینده پژوهشها بهگونهای منتشر میشوند که به راحتی توسط ماشینها قابل خواندن باشد، تا انسانها. همه این اشکال جدید انتشار وجود خواهد داشت.
در عصر مدلهای زبانی بزرگ، «آیزن» آیندهای را به تصویر میکشد که در آن یافتهها به صورت تعاملی مثلاً به جای یک محصول ثابت و یک اندازه در فرمت «paper on demand» منتشر میشوند. در این مدل، کاربران میتوانند از یک ابزار هوش مصنوعی برای پرسیدن سؤالات مربوط به آزمایشها، دادهها و تجزیه و تحلیلها استفاده کنند، این فرمت به آنها اجازه میدهد تا جنبههای یک مطالعه را که بیشتر مرتبط با آنها است، بررسی کنند. همچنین به کاربران این امکان را میدهد که به شرحی از نتایج که مطابق با نیازهای آنها است، دسترسی داشته باشند. «آیزن» میگوید: من فکر میکنم استفاده از روایتهای منفرد بهعنوان رابط بین افراد و نتایج مطالعات علمی، فقط نیاز به زمان دارد.
شرکتهایی مانند scite و Elicit قبلاً ابزارهای جستجویی را راهاندازی کردهاند که از مدلهای زبانی بزرگ برای ارائه پاسخهای به زبان طبیعی به پرسشهای پژوهشگران استفاده میکنند. در ماه آگوست (مردادماه)، انتشارات الزویر نسخه آزمایشی ابزار خود با نام Scopus AI را برای ارائه خلاصهای سریع از موضوعات پژوهشی راهاندازی کرد.
«پاتریک ماینو » اضافه میکند که ابزارهای هوش مصنوعی مولد میتوانند نحوه انجام متاآنالیزها و مطالعات مروری پژوهشگران را تغییر دهند؛ البته تنها در صورتی که این ابزار به ایجاد اطلاعات و رفرنسها تمایل داشتهباشد، این موضوع میتواند به اندازه کافی مورد توجه قرار گیرد.
بزرگترین مطالعه مروری تولیدشده توسط انسان که «پاتریک ماینو» دیده، شامل حدود ۱۶۰۰ مقاله است؛ اما با استفاده از هوش مصنوعی مولد، این مطالعه مروری میتواند بزرگتر شود. او می گوید: «این تعداد مقاله به نسبت کل پیشینه علمی موجود، بسیار ناچیز است. سؤال این است که در حال حاضر چه مقدار از این قبیل اطلاعات در ادبیات و پیشینه علمی وجود دارد که میتوان از آنها بهرهبرداری کرد؟
انتهای پیام

نظرات